示例表参照 Order by与Group by优化
背景
平时开发过程中在我们的业务系统实现分页功能 都会使用到如下sql实现
select * from employees limit 10000,10; |
这条语句表示在 employees 中取出从 10001 行开始的 10 行记录。看似只查询了 10 条记录,实际这条 SQL 是先读取 10010 条记录,然后抛弃前 10000 条记录,最后读到后面 10 条想要的数据返回。因此要查询一张大表比较靠后的数据,执行效率 是非常低的。
相信大家在工作时都遇到分页查询时,页码越靠后,查询越慢的情况。
场景及优化技巧
主键排序自增且连续
根据自增且连续的主键排序的分页查询,首先来看一个根据自增且连续主键排序的分页查询的例子:
该 SQL 表示查询从第 90001开始的五行数据,没添加单独 order by,表示通过主键排序。
select * from employees limit 90000,5; |
执行结果: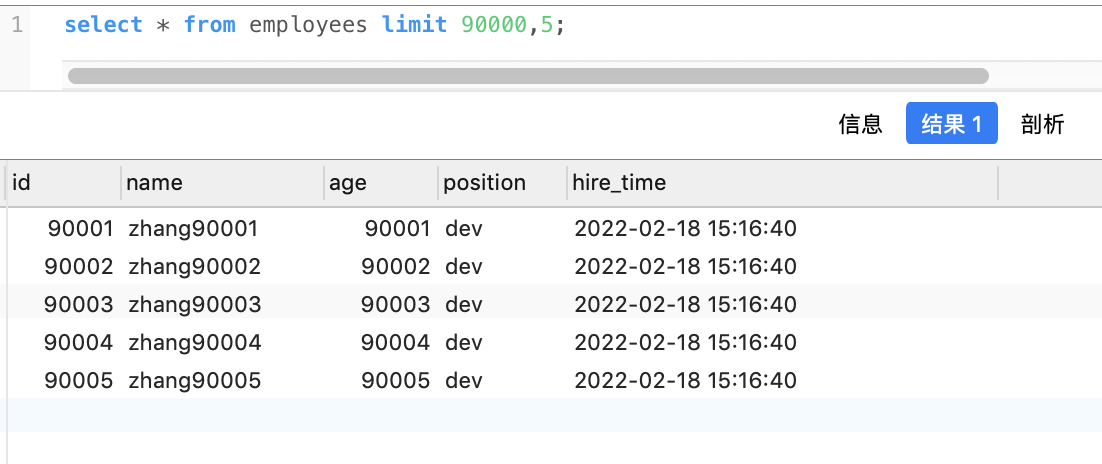
执行计划:
我们再看表 employees ,因 为主键是自增并且连续的,所以可以改写成按照主键去查询从第90001开始的五行数据,如下:
select * from employees where id > 90000 limit 5; |
执行结果: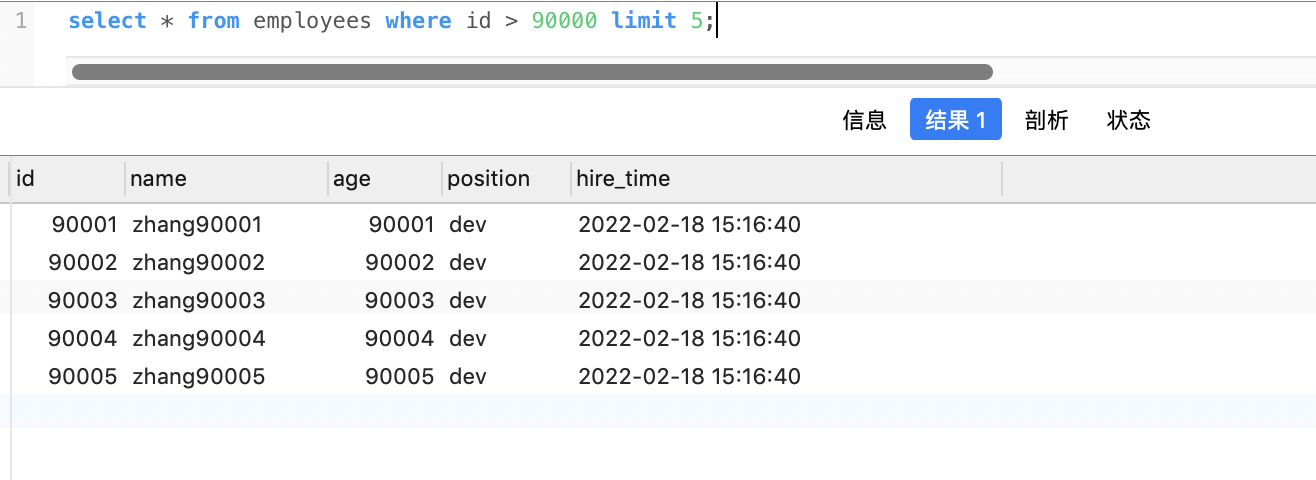
执行计划:
我们可以看到 执行结果是一致的。 但是对比 执行计划 时发现 显然改写后的 SQL 走了索引,而且扫描的行数大大减少,执行效率更高。
⚠️ 这条改写的SQL 在很多场景并不实用,因为表中可能某些记录被删后,主键空缺,导致结果不一致。使用时需要满足以下两个条件
- 主键自增且连续
- 结果是按照主键排序的
非主键排序
语句分析
select * from employees ORDER BY name limit 90000,5; |
执行结果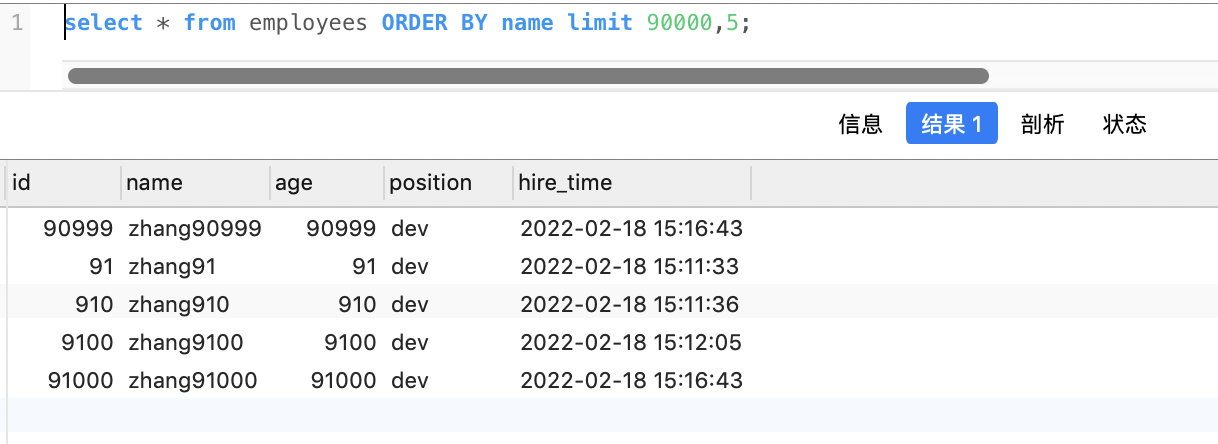
执行计划
通过执行计划发现并没有使用 name 字段的索引(key 字段对应的值为 null)
具体原因在MySQL Optimizer 分析(trace 工具)中讲过:
优化器判断使用索引的成本比扫描全表的成本更高,所以优化器放弃使用索引。
知道不走索引的原因,那么怎么优化呢?
其实关键是让排序时返回的字段尽可能少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录,SQL 改写如下:
select e.* from employees e inner join |
执行结果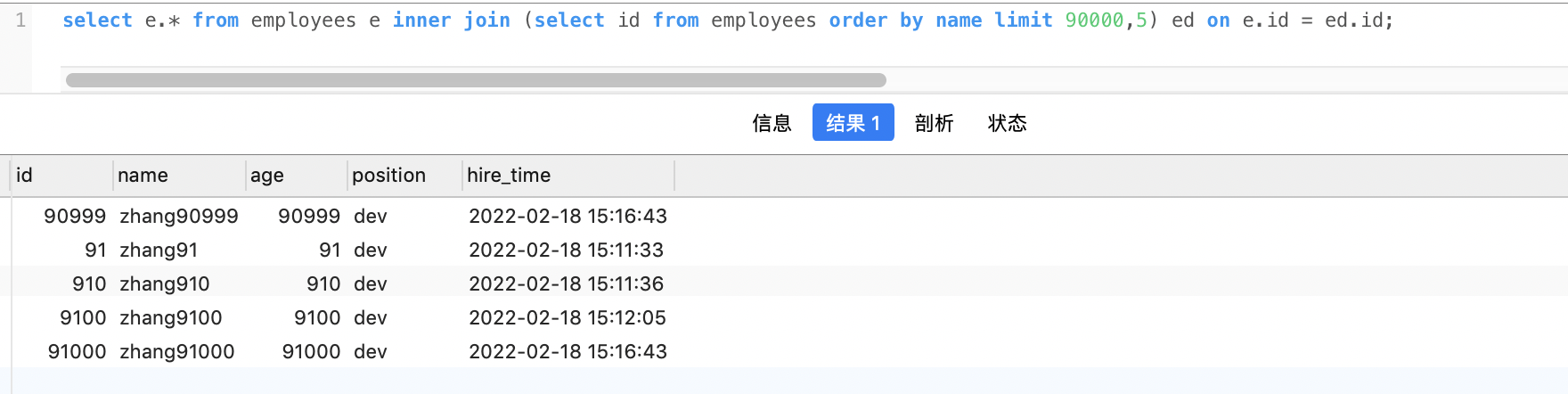
执行计划
需要的结果与原 SQL 一致,执行时间减少了一半以上,我们再对比优化前后sql的执行计划 可以看到 原 SQL 使用的是 filesort 排序,而优化后的 SQL 使用的是索引排序。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章