概述
锁是计算机协调多个进程或线程并发访问某一资源的机制。
在数据库中,除了传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供需要用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
锁分类
- 从性能上分为乐观锁(用版本对比来实现)和悲观锁
- 从对数据库操作的类型分,分为读锁和写锁(都属于悲观锁)
- 读锁(共享锁,S锁(Shared)):针对同一份数据,多个读操作可以同时进行而不会互相影响
- 写锁(排它锁,X锁(eXclusive)):当前写操作没有完成前,它会阻断其他写锁和读锁
- 从对数据操作的粒度分,分为表锁和行锁
表锁
每次操作锁住整张表。开销小,加锁快、不会出现死锁。锁定粒度大,发生锁冲突的概率最高,并发度最低。
一般用在整表数据迁移的场景。
案例
数据准备
# 建表 |
读锁
客户端A 加读锁
LOCK table mylock read;
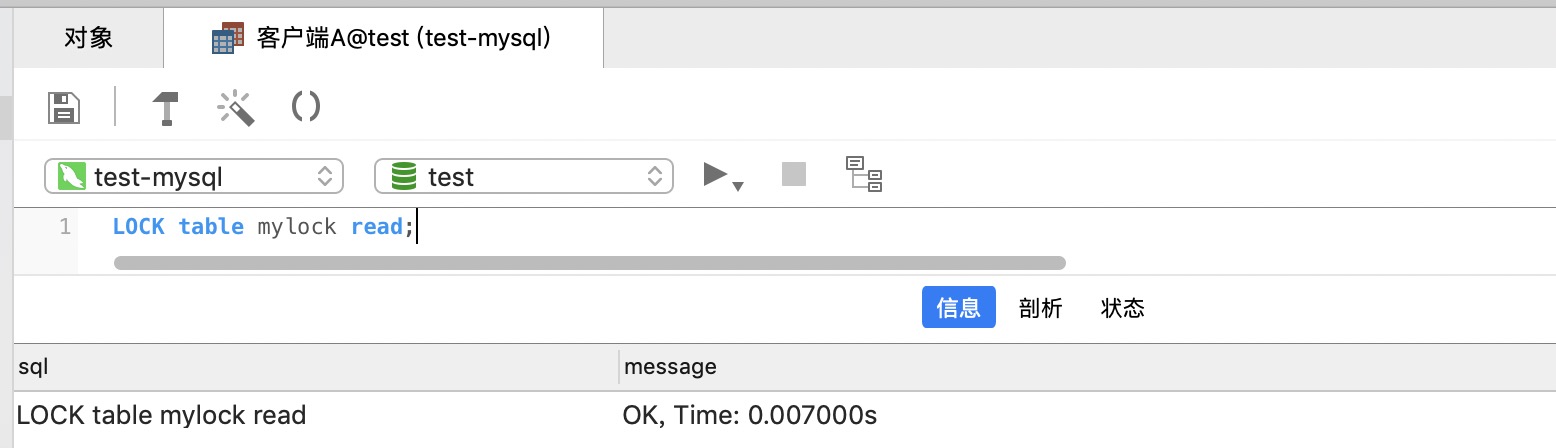
客户端A 查询表 mylock
SELECT * from mylock;
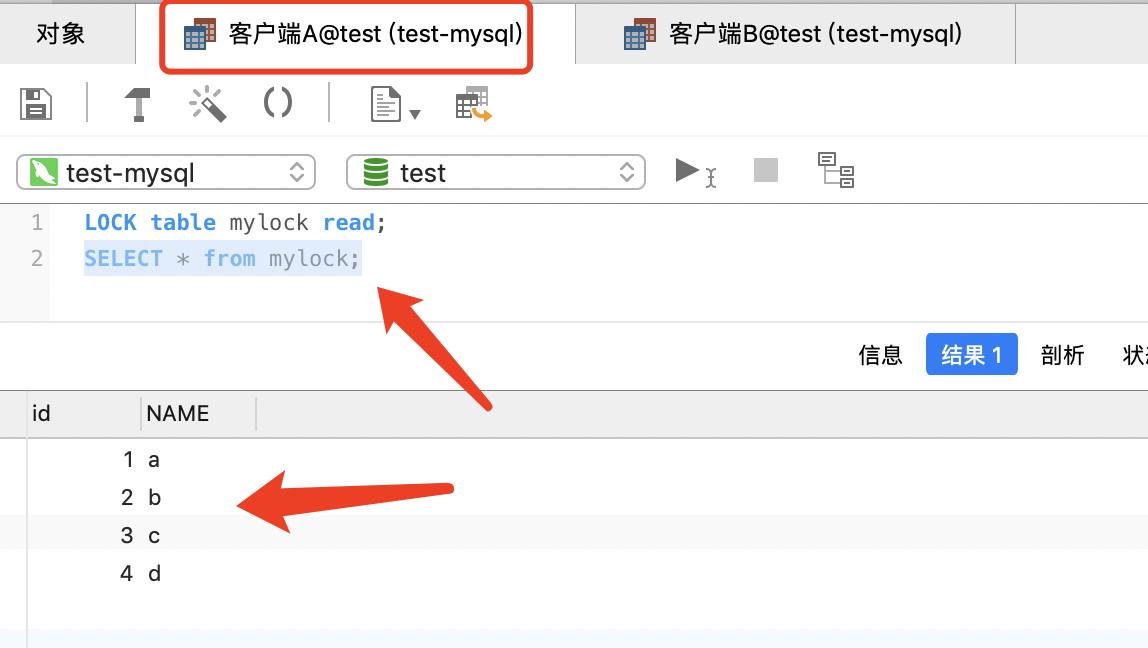
客户端B 查询表 mylock 数据
SELECT * from mylock;
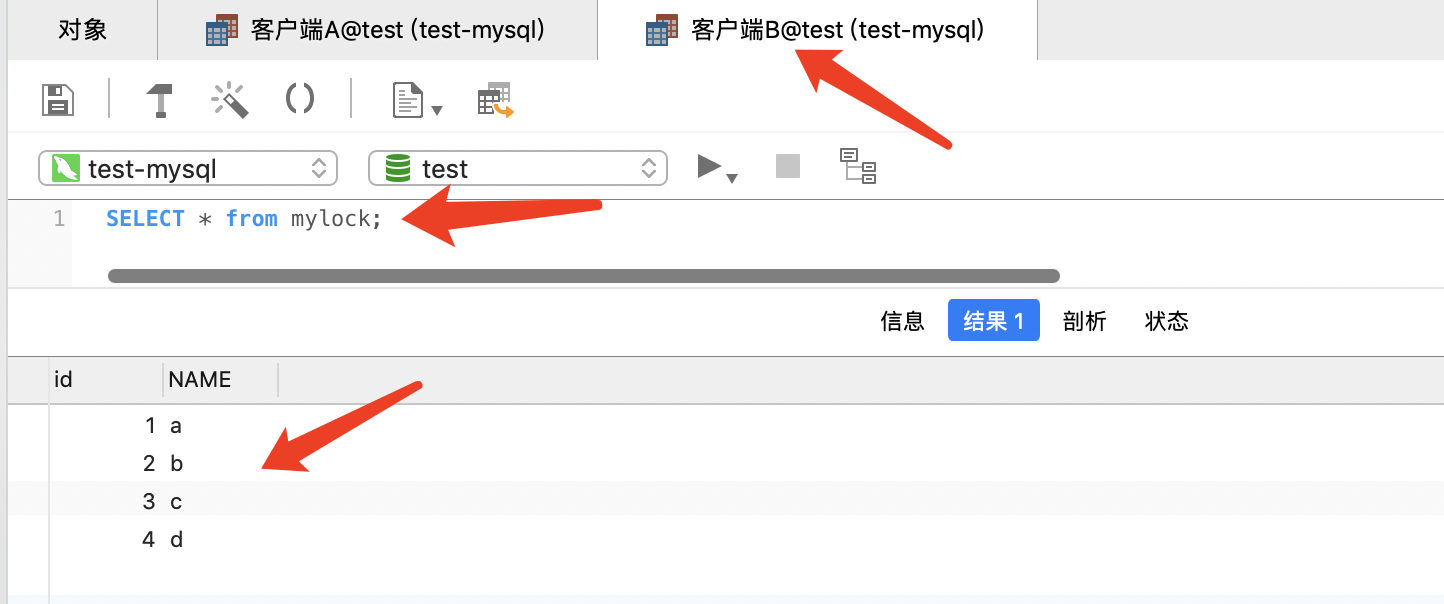
从3,4结果客户端A和客户端B都可以读该表,所以读锁不阻塞读
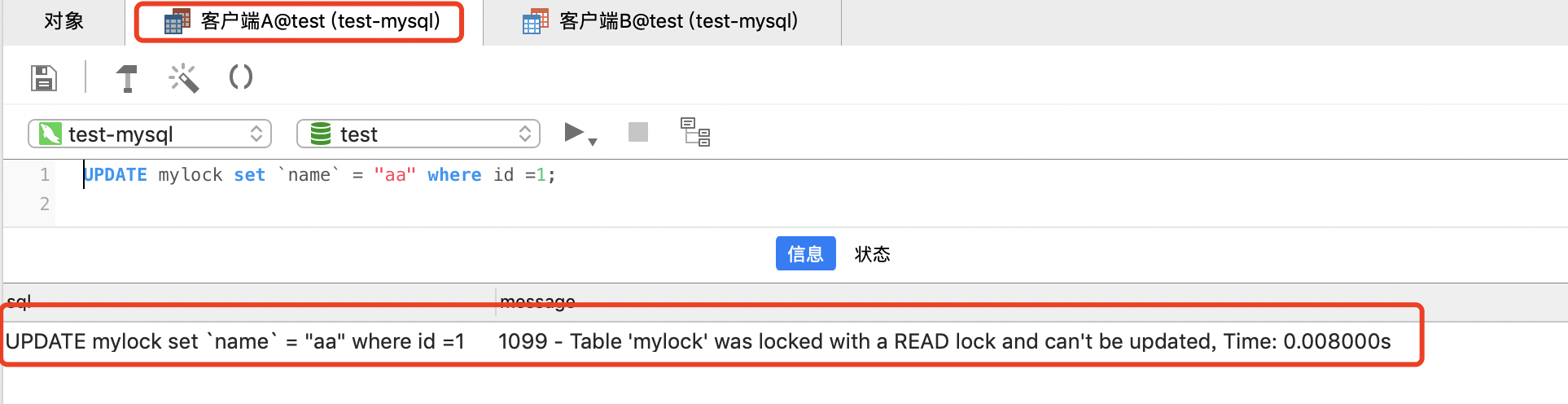
客户端A 插入或者更新锁定的表都会报错
UPDATE mylock set `name` = "aa" where id =1;
客户端B 插入或更新会等待
UPDATE mylock set `name` = "aa" where id =1;

写锁
客户端A对该表的增删改查都没有问题,客户端B对该表的所有操作被阻塞。(按照读锁的操作步骤自行实验,截图好累。。。。)
结论
1、对MyISAM表的读操作(加读锁) ,不会阻塞其他进程对同一表的读请求,但会阻塞对同一表的写请求。只有当读锁释放后,才会执行其它进程的写操作。
2、对MylSAM表的写操作(加写锁) ,会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其它进程的读写操作。
行锁
每次操作锁住一行数据。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度最 高。
一个session开启事务更新不提交,另一个session更新同一条记录会阻塞,更新不同记录不会阻塞
InnoDB与MYISAM的最大不同有两点:
- InnoDB支持事务(TRANSACTION)
- InnoDB支持行级锁
无索引行锁会升级为表锁
锁主要是加在索引上,如果对非索引字段更新,行锁可能会变表锁
客户端A 执行:update account set balance = 800 where name = ‘zhangsan’;
客户端B 对该表任一行操作都会阻塞住,InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。并且该索引不能失效,否则都会从行锁升级为表锁。
锁定某一行还可以用lock in share mode(共享锁) 和for update(排它锁),例如:select * from test_innodb_lock where a = 2 for update; 这样其他session只能读这行数据,修改则会被阻塞,直到锁定 行的session提交
MyISAM/InnoDB对比分析
MyISAM在执行查询语句SELECT前,会自动给涉及的所有表加读锁,在执行update、insert、delete操作会自 动给涉及的表加写锁。
InnoDB在执行查询语句SELECT时(非串行隔离级别),不会加锁。但是update、insert、delete操作会加行锁。
简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞。
行锁分析
通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况
show status like'innodb_row_lock%'; |
对各个状态量的说明如下:
| 状态量 | 说明 |
|---|---|
| Innodb_row_lock_current_waits | 当前正在等待锁定的数量 |
| Innodb_row_lock_time | (重要)从系统启动到现在锁定总时间 |
| Innodb_row_lock_time_avg | (重要)每次等待所花平均时间 |
| Innodb_row_lock_time_max | 从系统启动到现在等待最长的一次所花时间 |
| Innodb_row_lock_waits | (重要)系统启动后到现在总共等待的次数 |
当等待次数很高,而且每次等待时长也不小的时候,我们就需要分析系统中为什么会有如此多的等待, 然后根据分析结果着手制定优化计划。
死锁
set tx_isolation=’repeatable-read’;
Session_1执行:select * from account where id=1 for update;
Session_2执行:select * from account where id=2 for update;
Session_1执行:select * from account where id=2 for update;
Session_2执行:select * from account where id=1 for update;
查看近期死锁日志信息:show engine innodb status\G;
大多数情况mysql可以自动检测死锁并回滚产生死锁的那个事务,但是有些情况mysql没法自动检测死锁
间隙锁(Gap Locks)
间隙锁是封锁索引记录中的间隔(后面具体用例子讲解说明是间隔),或者第一条索引记录之前的范围,又或者最后一条索引记录之后的范围。间隙锁 在某些情况下可以解决幻读问题。
mysql间隙锁默认开启 查看间隙锁状态 传送门 ->mysql常用命令及配置
间隙锁的产生条件(RR事务隔离级别下)
- 使用普通索引锁定;
- 使用多列唯一索引;
- 使用唯一索引锁定多行记录。
案例一.唯一索引的间隙锁
数据环境: MySQL,InnoDB,默认的隔离级别 可重复读(RR)
数据准备
CREATE TABLE `gap_locks` ( |
开始之前 我们先来看看什么是间隙,id 字段的值 为 1 4 7 11 , 1-4这个区间内还空了 2,3 这两个值 这就是一个间隙。那么这张表一共有下面6个间隙(整个数据区间为 负无穷 到 正无穷)
- (-∞,1]
- (1,4]
- (4.7)
- (7,11]
- (11,15]
- (15,+∞]
我们首先打开两个mysql 会话 分别叫做客户端A 和 客户端B
- 客户端A 打开事务 进行批量更新 不提交事务。
BEGIN;
UPDATE gap_locks set name = '测试' where id > 5 and id < 14;
- 客户端B 分别插入各个区间中的 数据
# 客户端B插入一条 id = 3,name = '小张3' 的数据
INSERT INTO `gap_locks` (`id`, `name`) VALUES (3, '小张3'); # 正常执行
# 客户端B插入一条 id = 5,name = '小张5' 的数据
INSERT INTO `gap_locks` (`id`, `name`) VALUES (5, '小张5'); # 阻塞
# 客户端B插入一条 id = 8,name = '小张8' 的数据
INSERT INTO `gap_locks` (`id`, `name`) VALUES (8, '小张8'); # 阻塞
# 客户端B插入一条 id = 12, name = '小张12' 的数据
INSERT INTO `gap_locks` (`id`, `name`) VALUES (12, '小张12'); # 阻塞
# 客户端B插入一条 id = 16, name = '小张16' 的数据
INSERT INTO `gap_locks` (`id`, `name`) VALUES (16, '小张16'); # 正常执行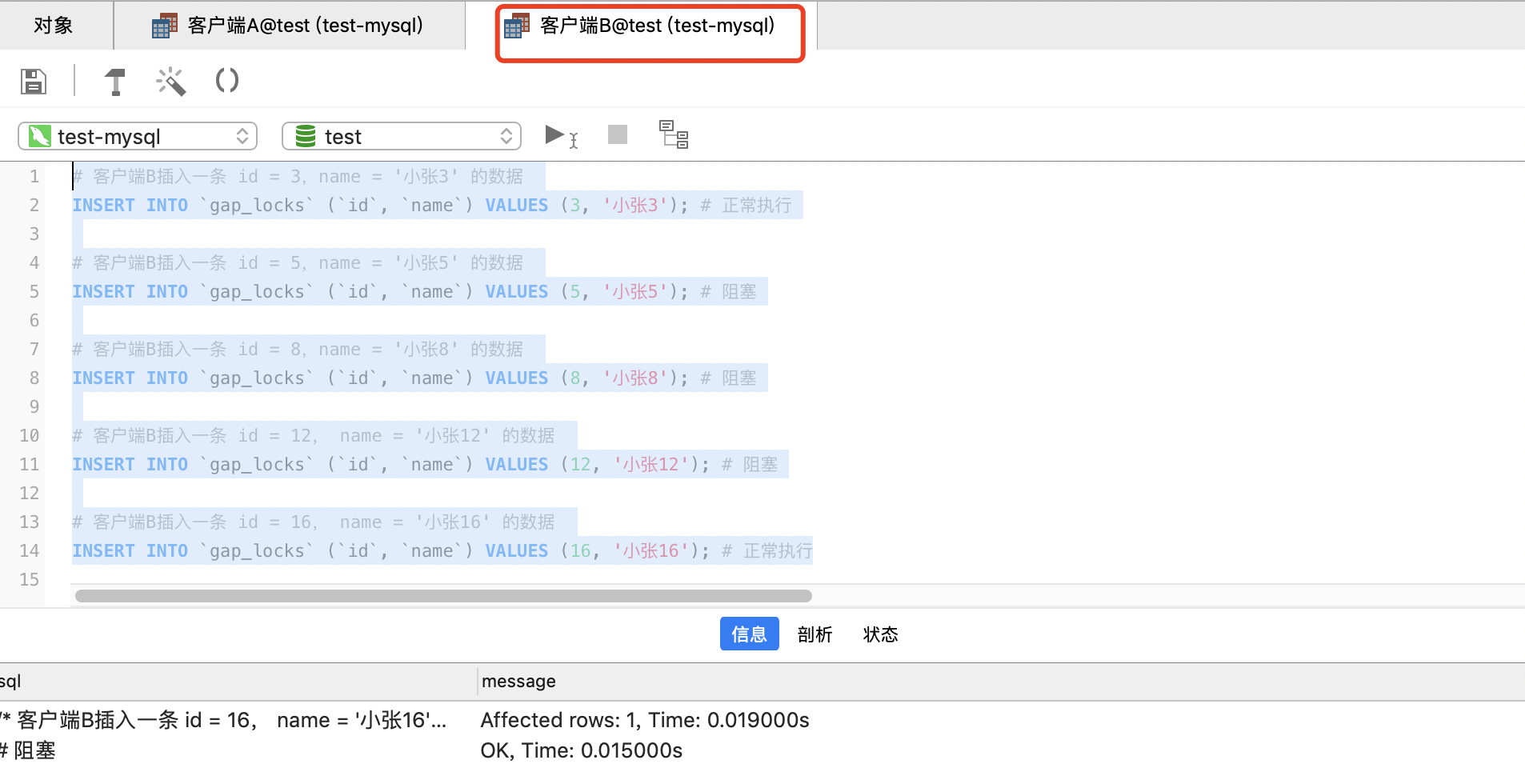
从上面我们可以看到,(4, 7]、(11, 15]这两个区间,都不可插入数据,其它区间,都可以正常插入数据。所以我们可以得出结论:当我们给 (5, 14] 这个区间加锁的时候,会锁住 (4, 7],(11,15] 这两个区间。
如果锁住不存在的的数据(截图太累此处直接给案例及结果)
- 客户端A 打开事务 更新不存在的数据 不提交事务。
BEGIN;
UPDATE gap_locks set name = '测试' where id = 3; - 客户端B 分别插入各个区间中的 数据
INSERT INTO `gap_locks` (`id`, `name`) VALUES (2, '小张2'); # 阻塞
INSERT INTO `gap_locks` (`id`, `name`) VALUES (3, '小张3'); # 阻塞
# 客户端B插入一条 id = 8,name = '小张8' 的数据
INSERT INTO `gap_locks` (`id`, `name`) VALUES (8, '小张8'); # 正常执行
# 客户端B插入一条 id = 12, name = '小张12' 的数据
INSERT INTO `gap_locks` (`id`, `name`) VALUES (12, '小张12'); # 正常执行
结论
结论
1.对于指定查询某一条记录的加锁语句,如果该记录不存在,会产生记录锁和间隙锁,如果记录存在,则只会产生记录锁,如:WHERE id = 5 FOR UPDATE;
2. 对于查找某一范围内的查询语句,会产生间隙锁,如:WHERE id BETWEEN 5 AND 7 FOR UPDATE;
普通索引的间隙锁
临键锁
临键锁(Next-key Locks)
Next-Key Locks是行锁与间隙锁的组合。像上面那个例子1里的这个(4,15]的整个区间可以叫做临键锁。
锁优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少检索条件范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的sql尽量放在事务最后执行
- 尽可能低级别事务隔离
INFORMATION_SCHEMA
查看INFORMATION_SCHEMA系统库锁相关数据表
#查看事务 |
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章